Thoughts on the Elixir language and its Phoenix framework after two years of professional work.
I am a seasoned web developer (working primarily with Ruby on Rails before) and someone who got an opportunity to work on a commercial Elixir project. During the past 2 years, I wrote a lot of Elixir, which I had to learn from scratch. I always found this kind of personal post interesting, so I figured I would write one for you.
Elixir
If you haven’t heard about Elixir yet, I recommend watching the Elixir Documentary featuring the creator José Valim for a start. I don’t remember exactly how I found out about Elixir, but most likely from some Ruby community news. I lurked around Elixir space, read many exciting blog posts, and was generally impressed. What drew me to Elixir? While many good things can be said for Elixir, I liked the idea of the preemptive scheduler and the per-process garbage collector. Why?
The preemtivness of Beam (the Erlang Virtual Machine) means that the system behaves reasonably under high load. That’s not a small thing. Being able to connect with a remote shell to your running system and still operate it despite the fact it’s under 100% load is quite something. A per-process GC then means that you don’t run GC most of the time while processing web requests. Both give you a very low latency. If you want to know what I am talking about, go and watch the excellent video by Saša Jurić The Soul of Erlang and Elixir. It’s the best video out there to realize what Beam is about.
Despite my interest, though, I never actually went and wrote any Elixir. I even told myself that I would most likely pass on Elixir. The problems at hand seemed solvable by Ruby/Rails, and forcing oneself to learn a language without commercial adoption is difficult. To my surprise, one Elixir project appeared out of nowhere in Prague, where I stayed at the time.
I was working on my book full-time, and without having any job per se I accepted :). The project itself is not public yet, so while I would love to tell you more about it, you will still have to wait for its public launch.
Language
On the surface, Elixir feels Ruby-like, but soon you’ll realize it’s very different. It’s a strongly-typed, dynamic, but compiled language. Overall it’s very well designed and features a modern standard library.
Here are Elixir basic types:
iex> 1 # integer
iex> 0x1F # integer
iex> 1.0 # float
iex> true # boolean
iex> :atom # atom / symbol
iex> "elixir" # string
iex> [1, 2, 3] # list
iex> [{:atom, "value"}, {:atom, "value2"}] # keyword list
iex> {1, 2, 3} # tuple
iex> ~D[2021-03-30] # sigil
iex> ~r/^regex$/ # sigil
As you can see, there are no arrays. Just linked lists and quite special keyword lists. We have symbols like in Ruby (with the same problems of mixing them with strings for keys access) and tuples that get used a lot to return errors (:ok vs {:error, :name}). I love how tuples make the flow of returning errors standardized (even though it’s not enforced in any way).
Then there are maps (kind of Ruby’s Hash):
iex> map = %{a: 1, b: 2}
%{a: 1, b: 2}
iex> map[:a]
1
iex> %{map | a: 3}
%{a: 3, b: 2}
And named structs:
iex> defmodule User do
...> defstruct name: "John", age: 27
...> end
Structs work similarly to maps, because it’s basically a wrapper on top of them.
We can use typespecs to add typing annotation for structs and function definitions, but they are limited. Elixir compiler won’t use them. Still, they help with documentation, and their syntax is actually nice:
defmodule StringHelpers do
@type word() :: String.t()
@spec long_word?(word()) :: boolean()
def long_word?(word) when is_binary(word) do
String.length(word) > 8
end
end
Arguably, we do get one of the best pattern matching out there. You can pattern match everything all the time. Thanks to pattern matching, you also almost don’t need static typing. Ruby is getting there as well, but could never really match the wholesome pattern matching experience of Elixir, which was designed around pattern matching from the beginning. You pattern match in method definitions on what arguments you accept, pattern match in case statements, and your regular code.
I really like pattern matching combined with function overloading:
def add(nil, nil), do: {:error, :cannot_be_nil}
def add(x, nil), do: {:error, :cannot_be_nil}
def add(nil, y), do: {:error, :cannot_be_nil}
def add(x, y), do: x + y
We could also pattern match on structs or use guard clauses:
def add(nil, nil), do: {:error, :cannot_be_nil}
def add(x, y) when is_integer(x) and is_integer(y) do
x + y
end
def add(x, y), do: {:error, :has_to_be_integer}
You can also make your own guards with defguard/1 so guards can be pretty flexible.
Elixir is not an object-oriented language. We practically only write modules and functions. This helps tremendously in understanding code. No self. Just data in and out of functions and composition with pipes. Unfortunately, there is no early return that could be useful.
Standard library
The standard library is excellent and well documented. It feels modern because it’s modern. If you tried Elixir before, you might remember having to use external libraries for basic calendaring, but that’s the past. It does not try to implement everything as the philosophy is that you can also rely on Erlang standard library. An example of that might be functions to work with ETS (Erlang Term Storage), rand, and zip modules.
Calling Erlang is without performance penalty, and when I encounter an Erlang call, it does not even feel weird. All-in-all it feels clean and well designed especially compared to Ruby, which keeps a lot of legacy cruft in the standard library.
ExDoc might be the first impressive thing you get to see in the Elixir world. Just go on and browse the Elixir docs. Beautifully designed and featuring nice search, version switching, day and night modes. I love it. And as for the code documentation itself, Elixir is amazing. So are the docs for the main libraries and modules (Phoenix, Absinth). Some not-so-common ones could use help, though.
Tooling
Elixir’s tooling is one of the best out there. Outside static type checking or editor support, that is. You get Mix which you use as a single interface for all the tasks you might want to do around a given project. From starting and compiling a project, managing dependencies, running custom tasks (like Rake from Ruby) to making releases for deployment. There is a standardized mix format to format your code as well:
$ mix new mix_project && cd mix_project
$ mix deps.get
$ mix deps.compile
$ mix test
$ mix format
$ mix release
A little annoying is the Erlang’s build tool rebar3 which you will use indirectly and which causes weird compilation errors:
==> myapp
** (Mix) Could not compile dependency :telemetry, "/home/strzibny/.mix/rebar3 bare compile --paths="/home/strzibny/Projects/digi/backend/_build/dev/lib/*/ebin"" command failed. You can recompile this dependency with "mix deps.compile telemetry", update it with "mix deps.update telemetry" or clean it with "mix deps.clean telemetry"
Luckily the helpful messages will guide you to fix it:
$ mix deps.get telemetry
Resolving Hex dependencies...
Dependency resolution completed:
...
$ mix deps.compile telemetry
===> Compiling telemetry
The question is, why it had to fail the first time?
Moving on from Mix, you’ll get to use the very nice IEx shell that I wrote about in detail already. My favorite things about IEx are the easy recompilation of the project:
iex(1)> recompile
And the easy and native way to set breakpoints:
iex(1)> break!(MyModule.my_func/1)
The only annoyance comes from Elixir data types and how they work. Inspecting lists require this:
iex(3)> inspect [27, 35, 51], charlists: :as_lists
"[27,35,51]"
Also, the Ruby IRB’s recent multiline support would be highly appreciated.
And there is more! Beam also gives you a debugger and an observer. To start Debugger:
iex(1)> :debugger.start()
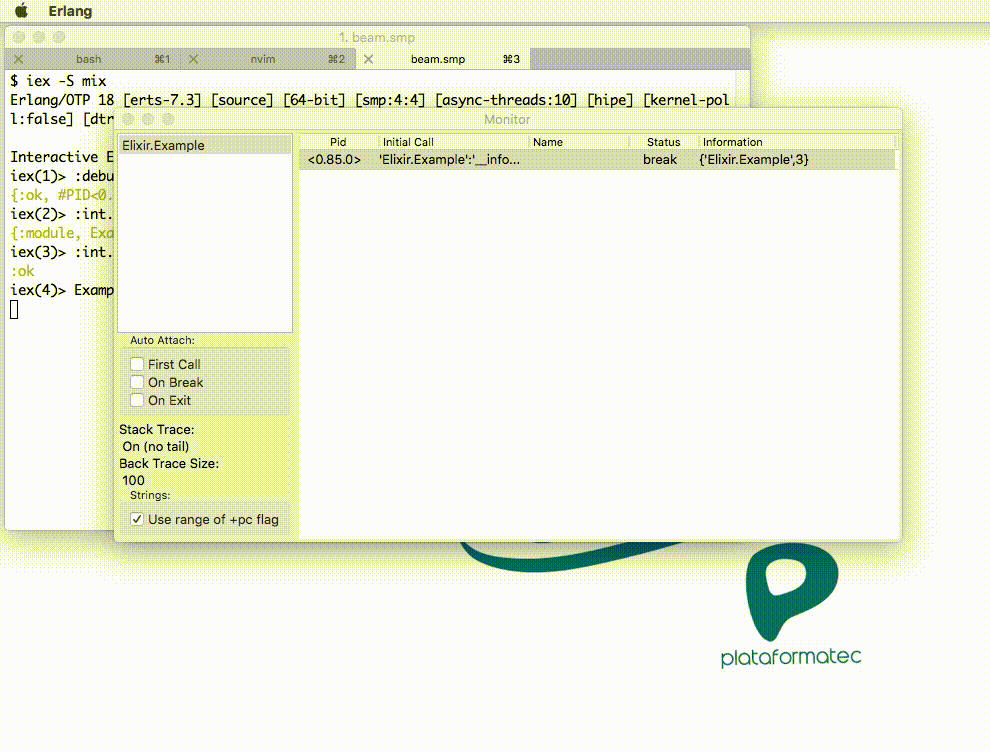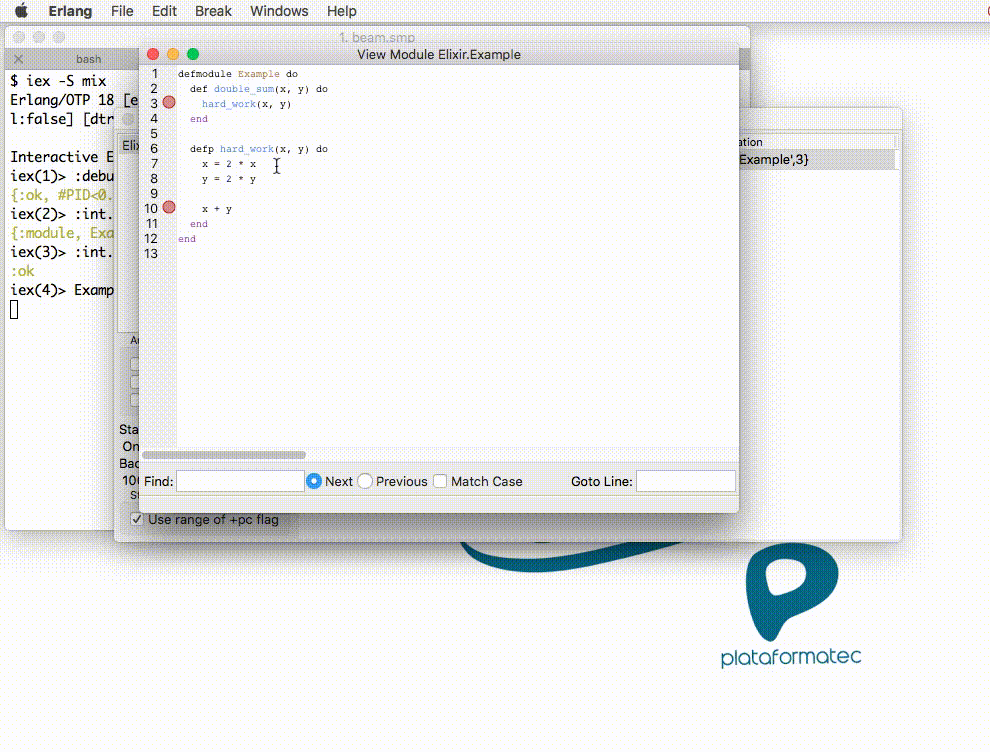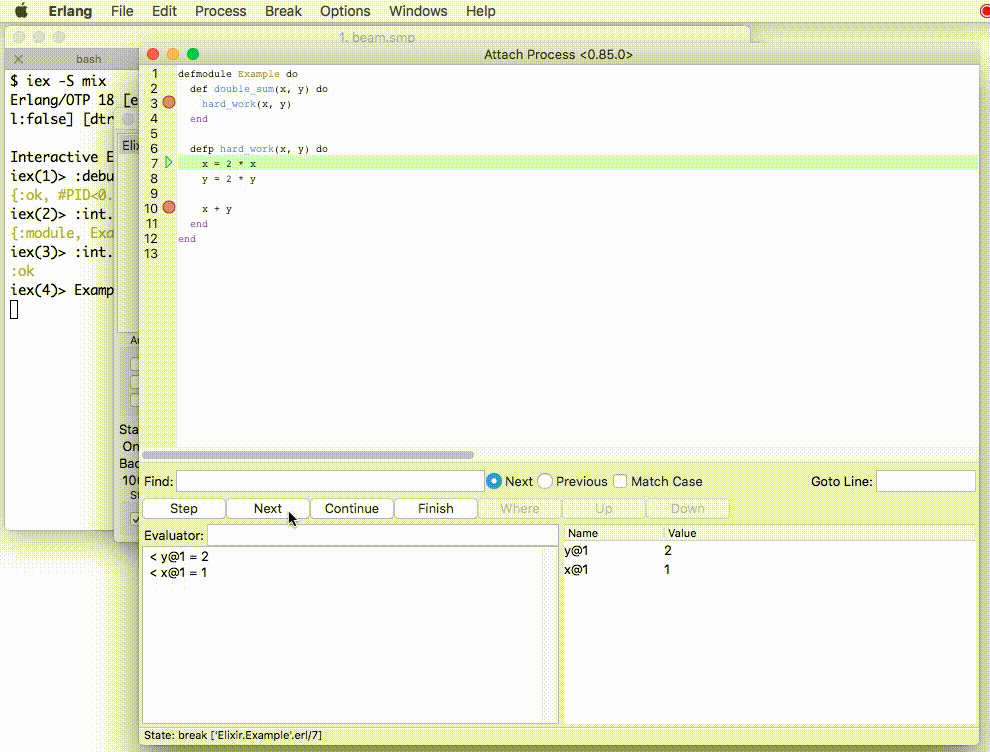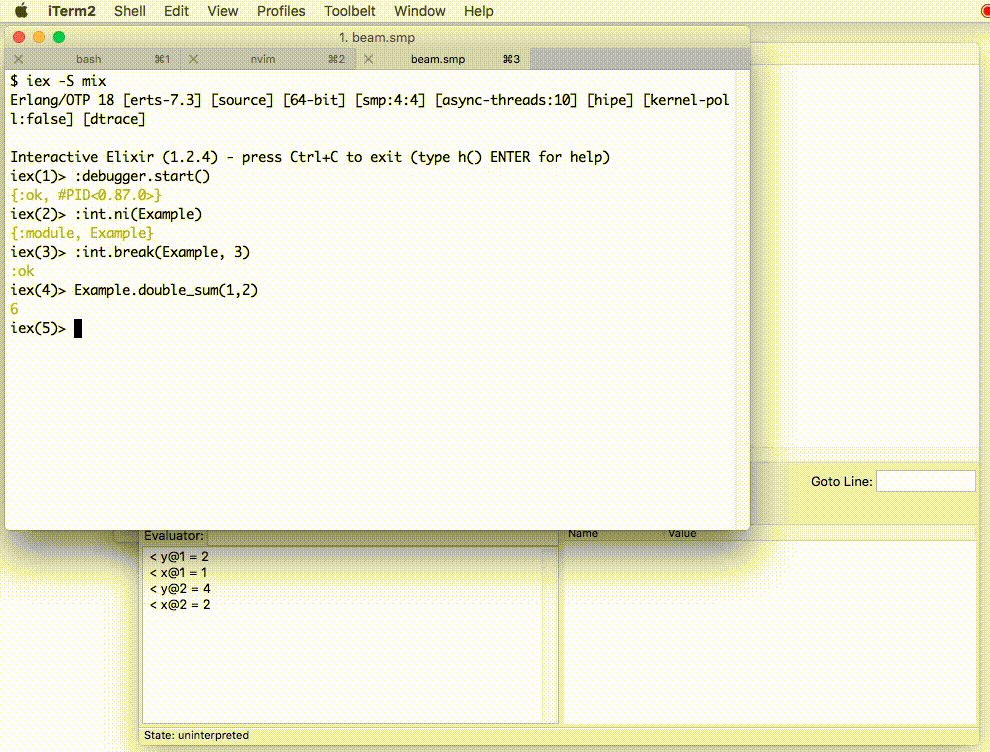
Image borrowed from the official page on debugging.
And Observer:
iex(1)> :observer.start()
They are both graphical.
Debugger’s function is clear, Observer helps to oversee the processes and supervision trees as Erlang VM is based on the Actor pattern with lightweight supervised processes. Coming from Ruby, I also like how the compiler does catch a bunch of errors before you get to your program. Then we have Dialyzer that can catch a ton of stuff that’s wrong, including the optional types from typespecs. But it’s far from perfect (both in function and speed), and so many people don’t run with it.
Most developers seek a great IDE or editor integration. I am using Sublime Text together with Elixir language server, and I documented the setup before. There is also a good plugin for IntelliJ IDEA that might be the best you can get right now. Elixir is not Java, but many nice things work.
The only real trouble for me is that my setup is quite resource-hungry. So while super helpful, I do tend to disable it at times. In general, I would say the editor support is somehow on par with Ruby, but I also believe Elixir’s design allows for great tools, we just don’t have them yet.
Testing
Testing Elixir code is pretty nice. I like that everyone uses ExUnit. One cool thing is doctests:
# Test
defmodule CurrencyConversionTest do
@moduledoc false
use ExUnit.Case, async: true
doctest CurrencyConversion
...
end
# Module
defmodule CurrencyConversion do
...
@doc """
Convert from currency A to B.
### Example
iex> convert(Money.new(7_00, :CHF), :USD)
%Money{amount: 7_03, currency: :USD}
"""
...
end
The above documentation’s example will be run as part of the test suite. Sweet!
The thing getting used to coming from Rails is mocking. While you might like the end result, it certainly is more tedious to write. This is because you cannot just override anything like in the Ruby world. When I use the Mox library, I usually have to:
- Write a behavior for my module (something like an interface)
- Use this behavior for my real module and my new stub (that will return a happy path)
- Register the stub with Mox
- Use configuration to set the right module for dev/production and testing
That way, you can easily test a default response and also use Mox to return something else for each test (such as an error response). I have a post explaining that.
The language nature of modules and functions ensures that your testing is straightforward, and multicore support ensures your test runs really really fast. The downside to a fast test suite is that you have to compile it first. So do not necessarily expect fast tests for your projects in CI. You will, however, see a considerable improvement over the Rails test suites once they get big.
Phoenix
Phoenix is the go-to web framework for Elixir. It’s neither Rails in scope but neither a microframework like Sinatra. It has some conventions, but you can change them without any big problem. Part of the reason for that is that it’s essentially a library, and also that you pair it with Ecto, your “ORM”. You write your Elixir application “with” Phoenix, not writing a Phoenix application (like with Rails).
Apart from being fast (Elixir is not fast perse, but templates are super-efficient, for example), it has two unique features that make it stand out even more.
One of those is LiveView, which lets you build interactive applications without writing JavaScript. And the second is LiveDashboard, a beautiful dashboard built on top of LiveView that you can include in your application in 2 minutes. It gives you many tabs of useful information about the currently running system (and you can switch nodes easily too). Some of those are:
- CPU, memory, IO breakdown
- Metrics (think telemetry)
- Request Logger (web version of console logs on steroids)
- web version of
:observer
I wish Phoenix had a maintenance policy like Rails so it could be taken more seriously. On the other hand, I think it doesn’t change as much anymore. Phoenix name and logo are also a nice touch as a reference to Beam’s fault tolerance (your Elixir processes will come back from the ashes).
Productivity
What’s important to me in a web framework is productivity. I don’t care I can craft the best performing applications in C, or have everything compiler-checked. I care about getting stuff done. I prefer frameworks that are designed for small teams because I want to be productive on my own. Phoenix is not batteries-included as Rails, although having features like LiveDashboard is probably better than having Action Text baked in. There are file uploads in LiveView, but it’s not a complete framework like Active Storage. So it’s behind Rails a little in productivity, but it’s still a very productive framework.
I am also convinced Phoenix scales better not only for hardware but also in terms of the codebase. I like the idea of splitting lib/app and lib/app_web from the beginning and the introduction of contexts. Context tells you to split your lib/app in a kind of service-oriented way where you would have app/accounting.ex or app/accounts.ex as your entry points to the functionality of your app.
Another interesting aspect is that since Phoenix is compiled, browsing your development version of the app is not slow like in Rails. It flies. Errors are also pretty good (and both error reporting and compiler warnings are improving every day):
constraint error when attempting to insert struct:
* unique_validation_api_request_on_login_id_year_week (unique_constraint)
If you would like to stop this constraint violation from raising an
exception and instead add it as an error to your changeset, please
call `unique_constraint/3` on your changeset with the constraint
`:name` as an option.
The changeset defined the following constraints:
* unique_address_api_request_on_login_id_year_week (unique_constraint)
But what I really really like? The development of Phoenix full-stack applications. No split between an Asset Pipeline and Webpacker (two competing solutions) and everything works without separately running your development Webpack server. You change a React component, switch to a Firefox window, and the change is there! And the only thing you were running is your mix phx.server.
But productivity cannot happen without good libraries. While Elixir and Phoenix eco-system has some outstanding options for things like GraphQL (Absinth) and Stripe (Stripity Stripe) there are not many good options for cloud libraries and other integrations. I feel like Stripe is the only exception here, but it’s not an official SDK.
Sometimes this is problematic as making your own SOAP library is not as much fun if you need to be shipping features involving SOAP at the same time. Sometimes, though, this can lead to building minimal solutions that are easy to maintain. We have practically two little modules for using object storage in Azure. I blogged before about how I implemented Azure pre-signing if you are interested.
Deployment
The deployment of Phoenix can be as easy as copying the Mix release I already mentioned to the remote server. You can then start it as a systemd service, for instance. While it wasn’t always straightforward to deploy Elixir web applications, it got ridiculously easy recently. Imagine running something like this:
$ mix deps.get --only prod
$ MIX_ENV=prod mix compile
$ npm install --prefix ./assets
$ npm run deploy --prefix ./assets
$ MIX_ENV=prod mix phx.digest
$ MIX_ENV=prod mix release new_phoenix
$ PORT=4000 build/prod/rel/new_phoenix/bin/new_phoenix start
Of course, you can make a light way Docker container too, but maybe you don’t even need to. Mix releases are entirely self-contained (even better than a Java’s JAR)! Here is how to make them with a little bit of context. The only thing to pay attention to is that they are platform-dependent, so you cannot cross-compile them easily right now.
Although people are drawn to Elixir for its distributed nature, its performance makes it a great platform for running a powerful single server too (which is how devs at X-Plane flight simulator run their Elixir backend). Especially since Elixir also supports hot deployments, which is kind of cool. Mix releases do not support this option, though.
Ecto
It’s hard to mention Elixir and Phoenix without a library that you’ll certainly add as well. Ecto is the database wrapper and query generator for Elixir. It’s split into four components. Ecto.Repo defines your repositories. They can be relational databases, but not necessary – Ecto is more flexible than that. Ecto.Schema and Ecto.Changeset define mapping of your data to Elixir structs and a way how to validate and change them. As you can see, Ecto follows a repository pattern, unlike Active Record. Ecto.Query then finish it up by allowing you to query your data in these repositories.
In practical terms, you’ll define your schemas twice – in a database migration and in the schema definition. While this is extra work you don’t have to resort to some generation tools adding your schema to models as comments. Plain Active Record classes are empty and everything is in a separate schema file.
The biggest difference comes from a repository pattern combined with schemas:
# Define for schema
def changeset(person, params \\ %{}) do
person
|> Ecto.Changeset.cast(params, [:first_name, :last_name, :age])
|> Ecto.Changeset.validate_required([:first_name, :last_name])
end
# Later
person = %Friends.Person{}
changeset = Friends.Person.changeset(person, %{first_name: "Ryan", last_name: "Bigg"})
Friends.Repo.insert(changeset)
Changesets encapsulates changes and validation logic. You create a changeset with your change and pass it to a repository. I find it a little bit more work, but once all is done, it feels very clean.
Another thing worth mentioning are composable transactions with Ecto.Multi. Here’s an example from the docs:
Multi.new()
|> Multi.update(:account, Account.password_reset_changeset(account, params))
|> Multi.insert(:log, Log.password_reset_changeset(account, params))
|> Multi.delete_all(:sessions, Ecto.assoc(account, :sessions))
|> MyApp.Repo.transaction()
With Ecto.Multi you define and name various stages of the transaction (which will give you an option to pattern match on errors). You can build it continuously. Once done, you pass it to a Repo.transaction. It takes a little time getting used to, but again I find it very clean in the end.
Community
The Elixir (and Phoenix) community is amazing. I always got quick and very helpful answers on Elixir Forum and other places. Elixir is niche. But it’s not Crystal or Nim niche. Still, it’s not an exception that you get answers directly from José Valim. How he can even reply so fast is still beyond me :). Thanks, Jóse!
Podium, Sketch, Bleacher Report, Brex, Heroku, and PepsiCo are famous brands using Elixir. Elixir Companies is a site tracking public Elixir adoption. I am myself on a not yet public project, so I am sure they are more Elixir out there!
If you are blogging about Elixir, join us at BeamBloggers.com. There is also ElixirStatus for community news.
Worth it?
And that’s pretty much it. If you are surprised I didn’t get into OTP, it’s because I didn’t get to do much OTP. It’s sure great (you reap the benefits just by using Phoenix), but you can use Elixir without doing a lot of OTP yourself.
The certain pros of Elixir are a small language you’ll learn fast, a modern, beautifully documented standard library, robust pattern matching, and understanding functions without headaches. What I don’t like is the same split for string vs atom keys in maps (without the Rails HashWithIndifferentAccess ) and I have to admit – there are times I miss my instance variables.
Learning Elixir and Phoenix is undoubtedly worth it. I think it’s technologically the best option to build ambitious web applications and soft-realtime systems we have today. It still lacks in few areas, but nothing that cannot be fixed in the future. And if not for Elixir, then for the Beam platform (see Caramel).
I also like that Elixir is not just a language for the web. There is Nerves for IoT, and recently we got Nx with LibTorch backend.

